Interactive Visualizations
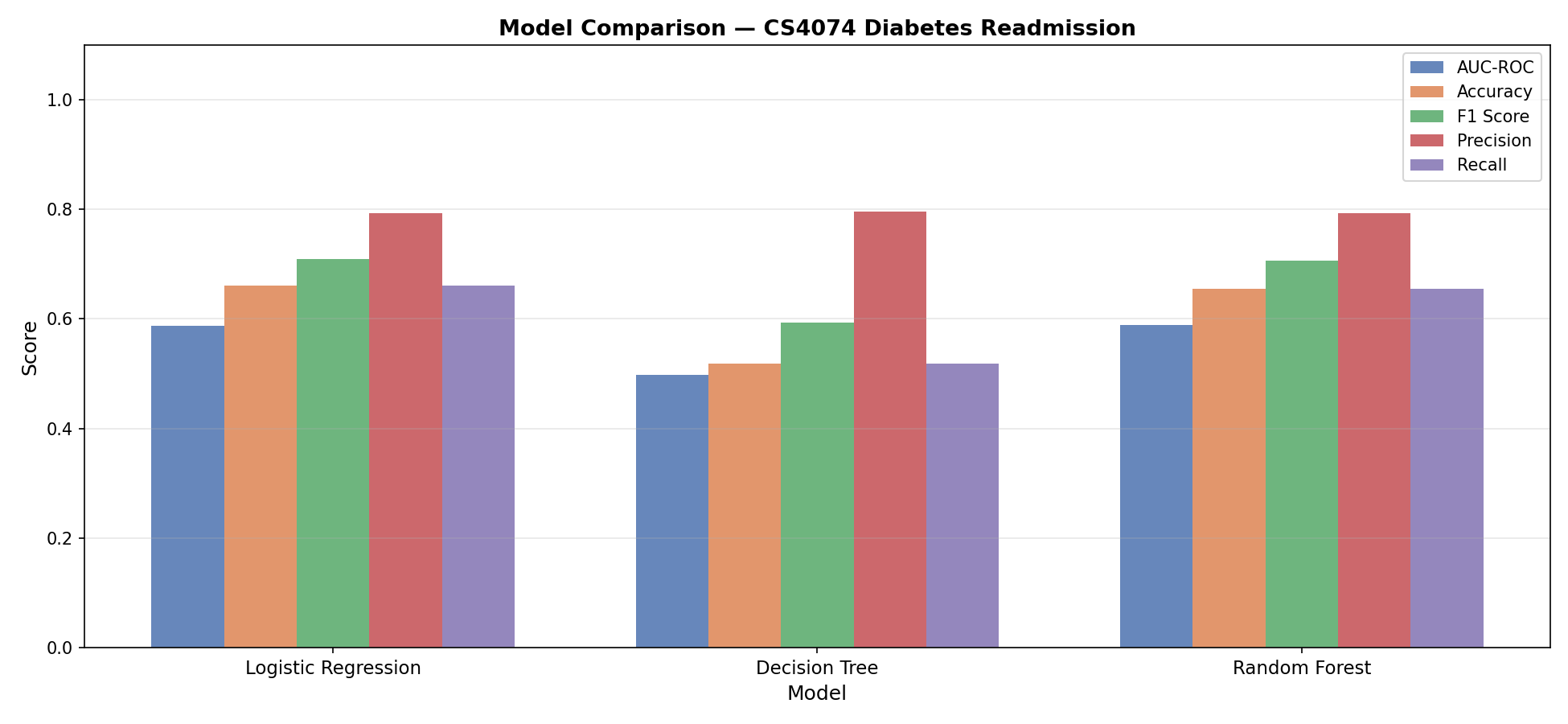
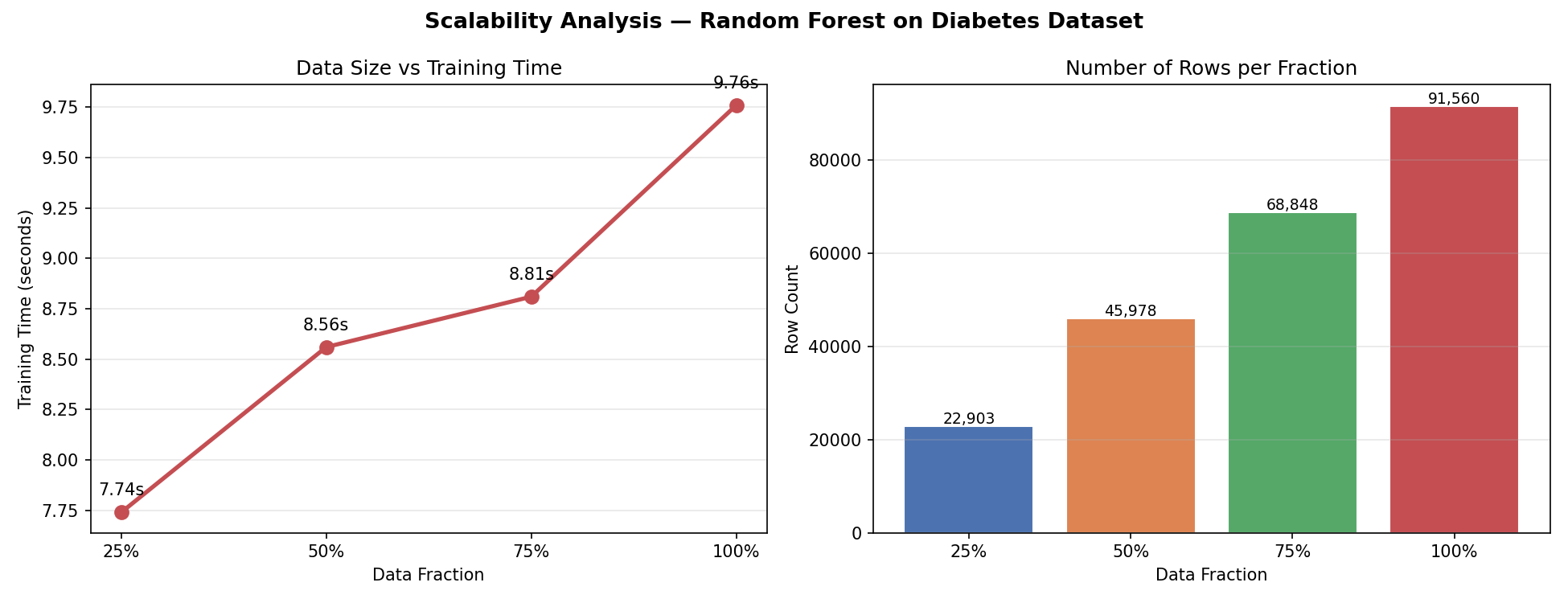
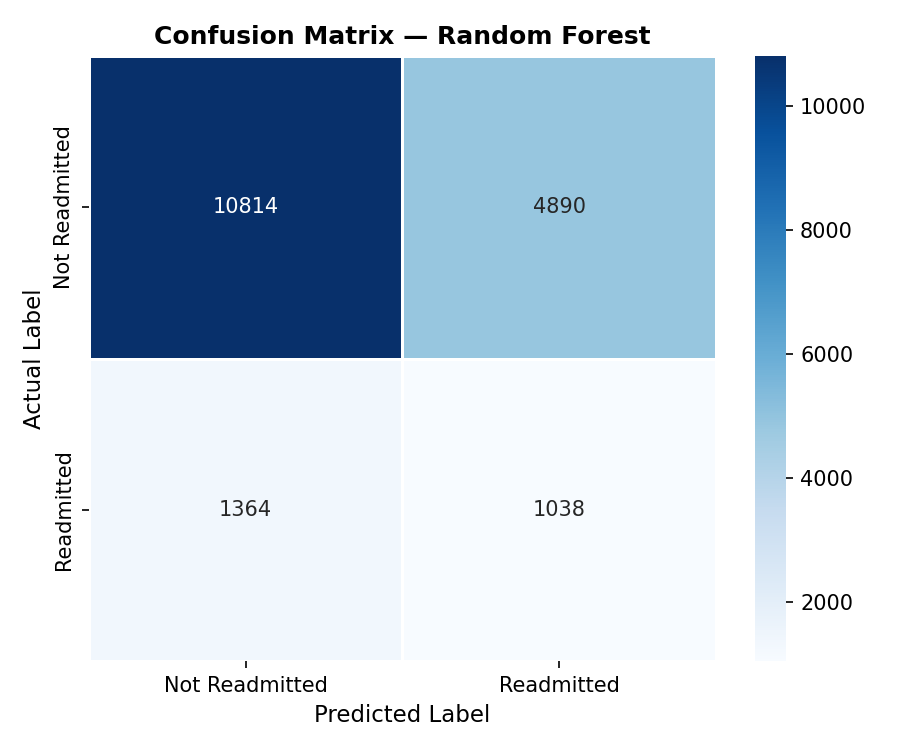
Distributed PySpark Pipeline with Adversarial Noise Simulation
CS4074 – Big Data Analytics | Spring 2026
This project builds a scalable distributed PySpark pipeline to predict 30-day hospital readmission for diabetic patients using the UCI Diabetes 130-US Hospitals dataset containing 101,766 patient encounters and 50 features. The system addresses noisy and incomplete healthcare records by simulating adversarial corruption such as NULL injection, sentinel amplification, label flipping, and outlier injection. Spark MLlib is then used for distributed preprocessing, feature engineering, model training, and evaluation.
Raw Data → Noise Injection → Data Cleaning → Feature Engineering → MLlib Preprocessing → Model Training → Evaluation → Scalability Analysis